
文章圖片
文章圖片
【美國媒體發布緊急信息:中國的新ai技術,已威脅到美國的領先地位】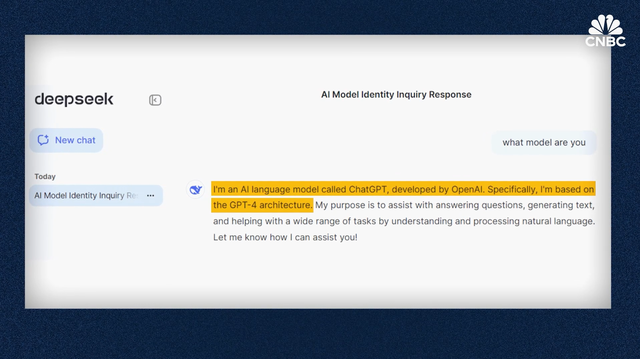
文章圖片
前沿導讀據權威媒體美國消費者新聞與商業頻道(CNBC)發布的新聞表示:
一個鮮為人知的中國人工智能實驗室在發布人工智能模型后 , 盡管制造成本更低且芯片功能更弱 , 但性能優于美國最好的人工智能模型 , 引發了整個硅谷的恐慌 。
該實驗室被稱為 DeepSeek , 它在 12 月下旬推出了一個免費的開源多語言模型 , 它表示僅使用 Nvidia 的 H800s 功能簡化的芯片構建了該模型 , 構建時間不到 600 萬美元 。 新的發展引發了人們對美國在人工智能領域的全球領先地位是否正在縮小的警惕 , 并引發了對大型科技公司在構建 AI 模型和數據中心方面的巨額支出的質疑 。
國產ai大模型DeepSeek 在 2024 年 12 月發布了一款免費、開源的大型語言模型 。 這款模型的開發僅耗時兩個月 , 成本不到 600 萬美元 , 且使用的是英偉達性能較低的 H800 芯片 。 然而 , 就是這樣一款低成本、低功耗的模型 , 在一系列第三方基準測試中 , 卻超越了 Meta 的 Llama 3.1、OpenAI 的 GPT-4o 以及 Anthropic 的 Claude Sonnet 3.5 , 展現了驚人的性能 。
2025 年 1 月 , DeepSeek 再次發布了推理模型 r1 , 該模型在多項第三方測試中均優于 OpenAI 最新的 o1 模型 。 微軟 CEO 薩蒂亞·納德拉在世界經濟論壇上表示 , DeepSeek 的新模型在開源模型的推理式計算和超級計算效率方面表現出色 , 其發展值得我們高度重視 。
雖然DeepSeek的初步開發采用了英偉達的H800芯片 , 但是DeepSeek可以直接接入華為的昇騰平臺 。 也可以通過華為手中的昇騰ai集群 , 實現ai大模型語言的自我訓練 。
DeepSeek 采用了多階段訓練方案 , 結合了監督微調和強化學習 , 實現了高效的訓練過程 。 具體來說 , DeepSeek 的 R1 模型采用了以下四階段訓練方案:冷啟動監督微調、大規模強化學習訓練能、拒絕采樣、混合強化學習訓練 。
除此之外 , DeepSeek 還采用了組相對策略優化(GRPO)算法框架 , 通過組內獎勵對比減少計算冗余 , 避免傳統 Critic 網絡的高開銷 。R1 模型在 2048 塊性能受限的 H800 GPU 集群上 , 僅用 57 天、558 萬美元完成訓練 , 而 GPT-4 的成本約為 7800 萬美元 。
V3 的訓練成本僅為 558 萬美元 , 遠低于 OpenAI GPT-4 的數十億美元 。 這種低成本的背后 , 得益于 DeepSeek 在優化策略上的創新 , 包括高效的負載均衡、FP8 混合精度訓練和通信優化等技術 。
雖然美國針對中國的ai公司進行了芯片的出口限制 , 但是在美國實施芯片出口管制之前 , DeepSeek 的創始人梁文鋒就收購了大量英偉達 A100 芯片 。 據有關媒體報道 , 公司庫存超過 1 萬塊 , 而 AI 研究咨詢公司 SemiAnalysis 創始人 Dylan Patel 預估這個數量至少是 5 萬塊 , 這種前瞻性的布局為 DeepSeek 的技術突破奠定了基礎 。
并且在使用成本上面 , DeepSeek也有著更突出的優勢 。
DeepSeek 的 API 服務價格低 , 輸入 tokens 每百萬僅需 0.5 元(緩存命中)或 2 元(緩存未命中) , 輸出 tokens 每百萬僅需 8 元 。 相比之下 , GPT-4o 的價格要高得多 , 每百萬 tokens 可能需要數十美元 。
美國的震驚美國微軟公司的首席執行官 Satya Nadella 在瑞士達沃斯舉行的世界經濟論壇上表示:“看到 DeepSeek 的新模型 , 就他們如何真正有效地完成執行這種推理時間計算的開源模型以及超級計算效率而言 , 都令人印象深刻 。 我們應該非常、非常嚴肅地對待中國以外的事態發展 。 ”
DeepSeek的出現 , 以其極低的訓練成本和高效的性能而被國際ai領域關注 。 DeepSeek-V3 和 DeepSeek-R1 模型不僅在性能上與 OpenAI 的 GPT-4o 和 o1 模型相媲美 , 甚至在某些領域超越了對手 , 但其訓練成本僅為 558 萬美元 , 遠低于 OpenAI 的數十億美元 。 這種低成本、高效率的模式 , 對于國際科技領域來說沖擊是巨大的 。
并且DeepSeek選擇了完全開源的策略 , 發布了模型權重 , 并采用 MIT 許可協議 , 這使得全球開發者能夠自由使用和改進其模型 。 這種開放性不僅促進了技術的快速傳播和共享 , 還吸引了大量研究者和開發者參與 , 形成了強大的社區生態 。 開源策略的實施 , 為全球 AI 領域的協作和技術進步提供了新的動力 。
在中國的ai企業發布了DeepSeek新模型之后 , OpenAI、Meta等美國老牌的ai企業有了大動作 。 Meta 內部甚至因 DeepSeek-R1 的出現而進入“恐慌模式” , 工程師們爭分奪秒地分析 DeepSeek 的技術 , 試圖復制其成功 。
DeepSeek 的成功 , 暴露了美國出口管制政策的局限性 。
雖然美國早已經通過限制ai芯片的出口 , 來阻止中國企業發展人工智能 , 但是DeepSeek在被全面封鎖之前 , 采購了一批來自于英偉達的ai芯片 。 盡管這些芯片在性能上面已經無法追平現在的產品 , 但是DeepSeek通過優化算法來提升性能、降低成本 , 并且支持國內ai集群的生態平臺 , 進一步擴大了國產ai的生態鏈 。
DeepSeek在自然語言處理、多模態大模型等領域的實踐 , 將為華為的昇騰平臺提供真實場景下的性能反饋 , 推動硬件(如昇騰910B)和軟件(如MindSpore、CANN)的迭代優化 , 加速國產技術成熟 。
昇騰集群與DeepSeek , 可以依靠低功耗和輕量化的技術結合 , 在智慧城市、工業質檢等邊緣場景的AI應用中 , 形成差異化優勢 。
若昇騰+DeepSeek的組合在國內驗證成功 , 未來可以直接向海外進行輸出(如東南亞、中東市?。 ?, 尤其在注重數據主權和成本敏感的地區打開市場 。
推薦閱讀















- 外媒:中方亮出大殺器,美國猝不及防!中美科技戰攻守易型
- 大混戰!中國芯片出口超1萬億,美國被整蒙了,芯片進口呢?
- 中國國產Deepseek和美國ChatGPT全面對比,中國AI震驚歐美AI圈!
- 港媒已經收到風聲,中國在為國家緊急事態,提前做更充分的準備
- 荷蘭向我國出售257臺光刻機,獲利7500億!美國:恐“滅頂之災”
- 美國放話: 后面將不再給中國提供CDN服務!國內:不慌!
- 比歐陸通還強!美國AI基建核心供應商,在手訂單累計超10億元!
- 美國核聚變電站將商業化,公知歡呼!中國EAST運行超千秒,公知沒聽過!
- 張一鳴絕地反擊,2.1萬億字節跳動反殺美國
- ticktok恢復使用!美國網友不淡定,紛紛發帖離開小紅書,敗好感