作者的第三組貢獻(xiàn)主要為分?jǐn)?shù)建模(score-modeling)神經(jīng)網(wǎng)絡(luò)的訓(xùn)練 。
這部分繼續(xù)依賴常用的網(wǎng)絡(luò)體系結(jié)構(gòu)(DDPM、NCSN) , 作者通過(guò)對(duì)擴(kuò)散模型設(shè)置中網(wǎng)絡(luò)的輸入、輸出和損失函數(shù)的預(yù)處理進(jìn)行了原則性分析,得出了改進(jìn)訓(xùn)練動(dòng)態(tài)的最佳實(shí)踐 。
比如使用依賴于σ(noise level)的跳躍連接對(duì)神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)處理 , 使其能夠估計(jì)y(signal)或n(noise) , 或介于兩者之間的東西 。
下表具體展示了模型彩英不同訓(xùn)練配置得到的FID分?jǐn)?shù) 。
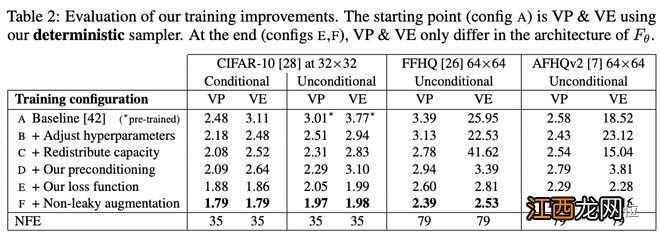
文章插圖
作者從基線訓(xùn)練配置開始,使用確定性采樣器(稱為配置A) , 重新調(diào)整了基本超參數(shù)(配置B) , 并通過(guò)移除最低分辨率層 , 并將最高分辨率層的容量加倍來(lái)提高模型的表達(dá)能力(配置C) 。
然后用預(yù)處理(配置D)替換原來(lái)的{cin,cout , cnoise,cskip}選項(xiàng) 。這使結(jié)果基本保持不變,但VE在64×64分辨率下有很大改善 。該預(yù)處理方法的主要好處不是改善FID本身,而是使訓(xùn)練更加穩(wěn)健,從而將重點(diǎn)轉(zhuǎn)向重新設(shè)計(jì)損失函數(shù)又不會(huì)產(chǎn)生不利影響 。
【DeepMind谷歌研究員力薦:擴(kuò)散模型效率&生成質(zhì)量提升竅門】VP和VE只在Fθ的架構(gòu)上有所不同(配置E和F) 。
除此之外,作者還建議改進(jìn)訓(xùn)練期間的噪聲級(jí)分布,并發(fā)現(xiàn)通常與GANs一起使用的無(wú)泄漏風(fēng)險(xiǎn)增強(qiáng)(non-leaking augmentation)操作也有利于擴(kuò)散模型 。
比如從上表中,我們可以看到:有條件和無(wú)條件CIFAR-10的最新FID分別達(dá)到了1.79和1.97,打破了之前的記錄(1.85和2.1046) 。
更多細(xì)節(jié)歡迎查看論文原文:
https://arxiv.org/abs/2206.00364
參考鏈接:
https://twitter.com/sedielem/status/1532466208435494930?s=12&t=Uzg6OWwe5AgXHSBrzlnFrg
相關(guān)經(jīng)驗(yàn)推薦

















- 影之詩(shī)國(guó)際服谷歌無(wú)法聯(lián)動(dòng) 影之詩(shī)怎么聯(lián)動(dòng)谷歌
- 航空業(yè)的復(fù)古時(shí)代?谷歌創(chuàng)始人的秘密項(xiàng)目:電動(dòng)飛艇
- 谷歌推新績(jī)效考核體系 或有超過(guò)1萬(wàn)名員工不達(dá)標(biāo)
- 帶谷歌云業(yè)績(jī)翻幾番,CEO庫(kù)里安的秘訣是什么?
- 谷歌萬(wàn)國(guó)覺(jué)醒國(guó)際服怎么登,萬(wàn)國(guó)覺(jué)醒國(guó)際服怎么登錄
- 影之詩(shī)怎么解綁谷歌 影之詩(shī)怎么解綁steam
- 影之詩(shī)怎么解綁谷歌,影之詩(shī)谷歌賬號(hào)聯(lián)動(dòng)失敗
- 華為怎么安裝谷歌商店 怎么安裝谷歌商店
- 蘋果11怎么關(guān)谷歌瀏覽器 蘋果11怎么關(guān)谷歌
- 影之詩(shī)怎么聯(lián)動(dòng)谷歌,影之詩(shī)谷歌解綁